 Campaign Creators
Campaign Creators

HubSpot Data Privacy for IT Teams: Permissions, Consent & Sensitive Data
HubSpot often sits at the center of your business operations. Marketing, sales, customer support, onboarding, billing workflows, and AI automation...

Many development teams mistake early success with a simple integration that only pulls a list of contacts as something ready for a live environment. Without planning for the deeper complexity, where most of the work involves authentication, rate limiting, and data normalization, many custom builds fail under real demand.
Building a durable architecture is the difference between a system that degrades under pressure and one that remains predictable as your business grows.
This article explains how you can move from script-based connections to a scalable, professional-grade HubSpot architecture.

The most significant gap in common HubSpot integrations is the tendency to treat the API as an unlimited, always-available data pipe rather than a shared resource with specific limits.
Most integrations do not hit platform limits because the business is unusually large, but because the request model is fundamentally wasteful. This gap typically manifests when a system is built for convenience rather than durability, leading to frequent 429 "Too Many Requests" errors and data inconsistencies.
Several specific design flaws contribute to this gap:
These gaps result in low-efficiency systems that fail to behave like durable production environments. Bridging this gap requires moving away from reactive "one-record" loops and toward a structured architecture that includes event layers, controlled queues, and automated integrity checks.
A multi-layered system designed to remain predictable as data volumes and business complexity increase is what a scalable HubSpot integration looks like. Rather than treating the API as an on-demand resource, a good architecture acts as a buffer, ensuring that the integration respects platform constraints while maintaining data integrity across systems.
For mid-market and enterprise environments, the most reliable production model follows a structured, layered approach:
Using this framework, you move from a fragile sync to a durable system that handles the deeper work, such as security, rate management, and recovery, that sits beneath a basic API connection.
To build a durable system, you must move away from low-efficiency patterns, such as one-by-one record processing, and adopt strategies that maximize every single request.
Effective limit management begins with knowing your specific constraints. For most public OAuth apps, the burst limit is 110 requests every 10 seconds. For private apps, the ceiling depends on your tier: Professional and Enterprise accounts allow 190 requests per 10 seconds, with daily limits of 1,000,000 requests.
You can track this budget in real-time by monitoring the X-HubSpot-RateLimit- headers provided in API responses.
Polling is manually asking the API on a timer if anything has changed. It spends your budget to answer binary questions that are often "no". By implementing HubSpot Webhooks or workflow-triggered events, your system receives real-time notifications only when a meaningful change occurs. This ensures that API calls are only made when there is actual work to perform.
Processing records individually is a prototype mistake that leads to rapid rate-limiting in production. HubSpot provides dedicated Batch APIs for reading, updating, and managing associations, which should be used wherever possible to reduce total request volume.
Furthermore, utilizing the Search API helps you to fetch up to 200 records per call, effectively cutting your request volume in half compared to standard list endpoints.
Many integrations are unnecessarily noisy because they repeatedly fetch information that rarely changes. Metadata such as property definitions, object schemas, and owner lists should be treated as configuration data. You can avoid burning your transaction budget on static structural information when you store it in a local cache and only refreshing them on a schedule.
A problem often occurs when multiple independent workers, such as a real-time sync, a nightly cleanup, and a reporting export, all hit HubSpot simultaneously. To prevent this, you should centralize your request logic using a "token bucket" or rate-limiting library. In this model, all workers must request a "token" from a shared handler before calling the API, ensuring the total combined traffic never exceeds the 10-second burst window.
When a 429 "Too Many Requests" error does occur, it should be treated as a diagnostic signal to slow down. Instead of immediate retries, which create "retry storms," the system should use exponential backoff with jitter. This adds a progressive and random delay between attempts to allow the API to recover.
For persistent failures, implementing circuit breakers can temporarily halt all traffic to an endpoint, preventing cascading failures across your entire infrastructure.
Your integration often serves as a bridge to sensitive CRM data; security cannot be an afterthought. A production-grade architecture must account for modern protocol standards, aggressive token expiry windows, and rigorous credential storage.
For optimal security, all public apps must use the OAuth 2.0 protocol directly. While private apps are available for single-account internal tools, they also utilize access tokens rather than legacy static API keys, which have been sunset by HubSpot.
OAuth 2.0 is the industry standard because it allows you to grant specific permissions without exposing private credentials, acting as a "front door key" that can be easily managed or revoked.
In January 2026, HubSpot reduced the lifespan of OAuth access tokens from six hours to 30 minutes. This means your architecture must include proactive refresh logic.
When configuring your app, you must carefully define OAuth scopes to ensure the application only has access to the data it strictly requires.
For example, if your integration only needs to view contact data, request crm.objects.contacts.read but avoid .write scopes. Over-provisioning scopes increases your security surface area unnecessarily; if a property or object isn't explicitly requested via scopes, it remains inaccessible.
Your OAuth tokens are essentially passwords to your customer's CRM and must be treated as such.
When using webhooks for real-time synchronization, your infrastructure must verify the HMAC signature of every incoming payload. This step uses your app secret to ensure the "push" notification actually originated from HubSpot and hasn't been intercepted or forged by a third party.
Never test new authentication or data-writing code in a live production environment. HubSpot provides a free Developer Portal where you can create sandbox accounts. This helps you to test with mock data and verify your security logic without the risk of corrupting or deleting critical business information.

Native connectors are pre-built integrations that link HubSpot directly to popular third-party platforms using standard field mappings and workflows. They are the ideal choice when your requirements align with standard business processes, and the connector supports your necessary data fields without modification.
Middleware (including iPaaS, unified APIs, or bespoke builds) becomes necessary when your business processes, data structures, or volume requirements exceed the out-of-the-box capabilities of a marketplace app.
In many enterprise implementations, a hybrid architecture is the most effective strategy. In this model, native connectors are used for standard, low-stakes processes to save development time, while custom middleware manages business-critical requirements that demand specific functionality or deep data normalization. This makes it possible for organizations to scale quickly without incurring unnecessary technical debt from forcing complex processes into limited native tools.
To ensure your integration can support advanced AI and machine learning (ML) applications, focus on the following architectural requirements:
AI and ML models are highly sensitive to data quality. Missing values, duplicates, and inconsistent formats can significantly degrade model performance. A clean data structure is the essential foundation that allows AI agents to accurately interpret intent and tone.
Integrations should prioritize schema normalization, mapping HubSpot’s custom properties into a standardized internal format, to ensure the AI is not fighting against "property sprawl" or fragmented records.
Modern AI agents require context beyond a single record. Preparing for RAG involves using vector embeddings to translate CRM data into numerical representations that capture semantic meaning rather than just keywords. This helps the system to find similar historical issues or relevant knowledge base articles to produce validated, contextually relevant responses.
To avoid writing massive amounts of "glue code" for every AI agent, utilize modern standards like the built-in MCP tool generation. This approach automatically exposes HubSpot resources as AI agent tools with generated JSON schemas, allowing Large Language Models (LLMs) to perform function calling directly on CRM objects without custom wrappers.
Reliable AI workflows must know when to stop. Your integration should include conditional logic to evaluate factors like the AI’s confidence score or the complexity of a technical issue.
If confidence is low or a high-severity label is detected, the system should trigger a human handoff, updating the HubSpot record with the AI’s suggested priority and technical context for a human agent to review.
In highly regulated industries like finance or healthcare, it is crucial to understand how an automated decision was reached. Ensure your integration logs the specific AI prompts, retrieved context, and logic paths used for each transaction, providing the transparency required for auditing and continuous optimization.
If you design your integration with these constraints from the start, you avoid rebuilding your entire system later when AI use cases shift from experimentation to real operational dependency.
A scalable integration is not something you layer on later. Every shortcut taken at the beginning, from polling to loose data structures, quietly sets limits on how far your system can grow. If you treat your integration as infrastructure instead of a connector, your decisions start to prioritize control, predictability, and long-term reliability instead of short-term convenience.
As your use cases expand into automation and AI, the integration stops being a background system and becomes a core part of how your business operates.
If you want your integration built on this kind of foundation from the start, explore our HubSpot Onboarding Services and set up a system that can handle scale, automation, and AI without constant rework.
HubSpot often sits at the center of your business operations. Marketing, sales, customer support, onboarding, billing workflows, and AI automation...
The modern enterprise tech stack has shifted from a single system to a mix of specialized SaaS tools. That shift creates a problem: CRM, payments,...
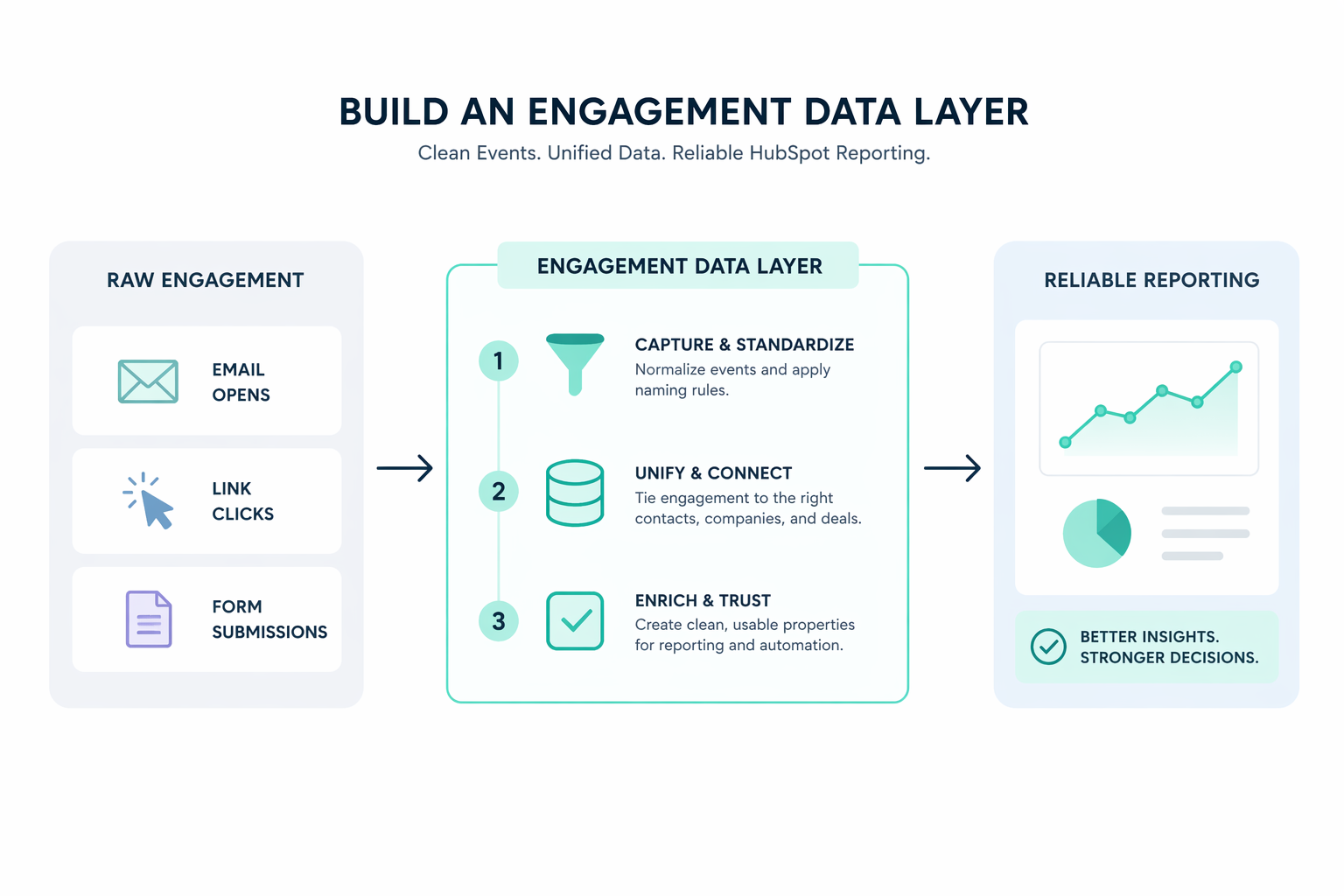
How to Build an Engagement Data Layer for Reliable HubSpot Reporting Consistent and accurate HubSpot reporting starts with the structure behind the...