 Campaign Creators
Campaign Creators
Data Contracts in HubSpot: Fix Property Sprawl and CRM Data Drift
Most CRM environments evolve without a defined schema strategy. Teams create properties to solve immediate problems, integrations introduce new...
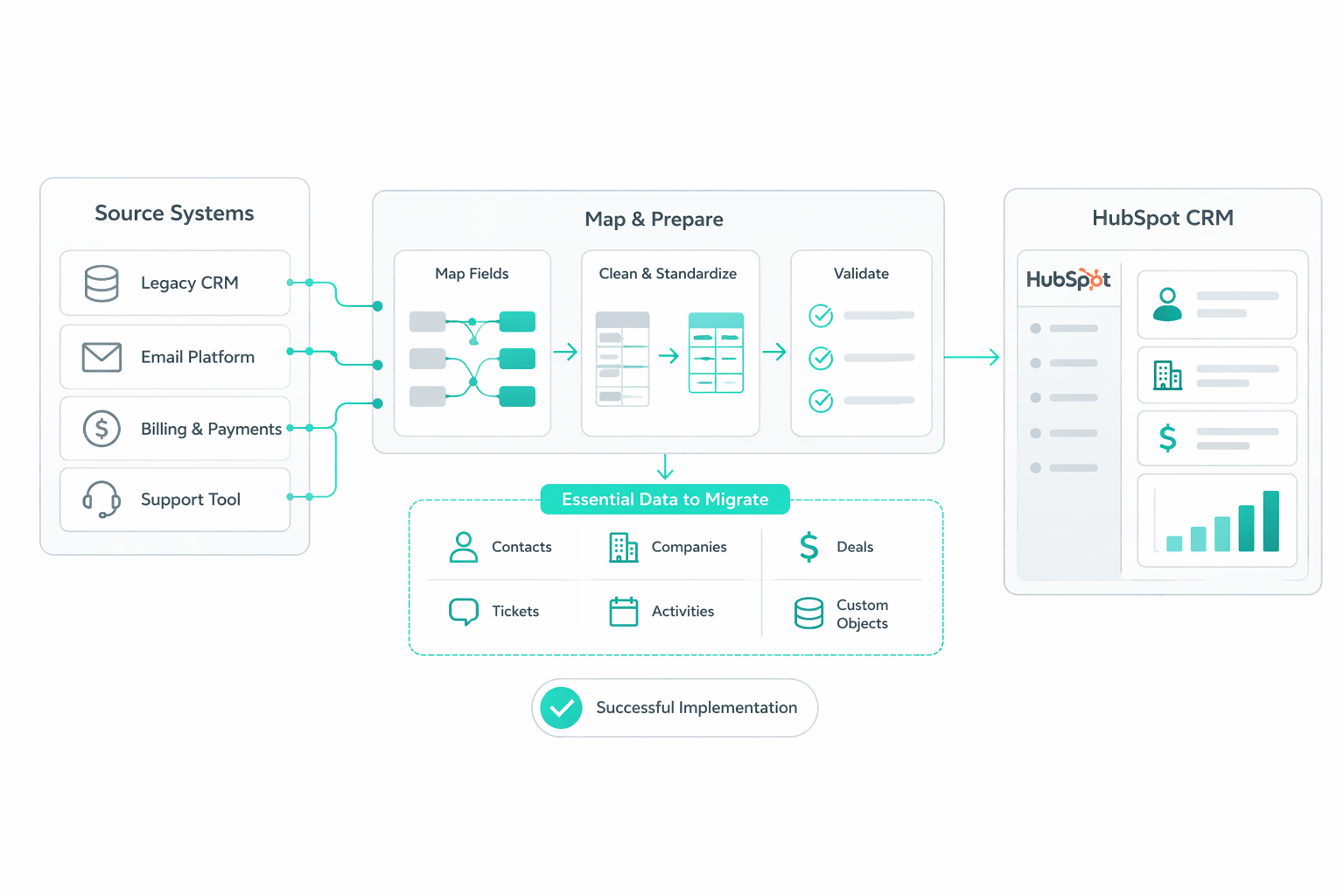
A HubSpot migration represents open-heart surgery on a company's revenue engine. It creates an opportunity to move away from decentralized, unreliable data and toward a single source of truth for every prospect interaction.
However, the complexity of this transition depends on factors such as data volume and the level of customization required. Without a structured approach, migrations often carry over the same data issues that existed before. Gartner reports that poor data quality costs organizations an average of $12.9 million annually, often driven by duplicates, inconsistencies, and incomplete records.
To avoid this, the focus should be on maintaining well-structured records and standardized formats from the start. This prevents the CRM from becoming cluttered and ensures the system remains usable across teams. This guide walks through the steps you can take to protect your revenue foundation and build a CRM that delivers reliable insights for long-term growth.
Contact and company data form the core of your CRM. Every report, automation, and revenue insight depends on how clean and structured these records are.
A large database often includes outdated contacts, duplicate entries, and incomplete profiles. Moving everything weakens segmentation and reporting. A strong dataset starts with clear inclusion criteria. Focus on contacts and companies that:
Older records, especially from trade shows or bulk imports, often inflate database size without adding value, which leads to weaker targeting and unreliable reporting.
Moreover, carrying unnecessary data increases complexity and reduces usability across teams. A smaller, more engaged dataset improves email performance, reporting clarity, and targeting precision from the start.
Legacy CRM data often contains inconsistencies that break automation and reporting. Common issues include:
HubSpot relies on structured data. Contacts are typically deduplicated using email, and companies use domain names as unique identifiers. Before migration, run a full deduplication process in a spreadsheet using tools such as VLOOKUP or conditional matching.
Your data cleaning should focus on removing duplicates and merging records correctly, retaining the earliest create date and the most recent activity during merges, filling missing critical fields, and standardizing formats such as job titles, industries, and lead sources
Every field in your legacy CRM needs to map correctly into HubSpot. Poor mapping leads to broken automation, unreliable reporting, and confusion across teams.
HubSpot’s import process depends on aligning spreadsheet columns with CRM properties, which define how records behave inside the system. Here is an example that you should follow:

You also need to audit every custom property before migration. Fields that have not been updated in the last 90 days or lack a clear purpose often add clutter without value and should be excluded.
Migration is a chance to simplify your data model. So removing redundant or unused properties reduces clutter and improves long-term maintainability.
Each contact should link to the correct company, with company records holding shared attributes such as industry, size, and revenue. HubSpot can automatically associate contacts using company domains, but this logic does not always work for complex structures such as multi-brand organizations or subsidiaries.
Imports can include multiple objects in one file to preserve these associations, ensuring records stay connected rather than isolated.
Broken or missing associations create gaps in reporting and reduce trust in the CRM. Clean relationships provide:
Every contact should connect to a company to avoid orphaned records and give sales teams complete account context.
A clean foundation makes every future initiative easier to execute, from reporting to personalization. Instead of inheriting years of inconsistent data, your CRM starts as a system your team can trust and actually use.
Deal and pipeline data represent your revenue story. Every closed deal, lost opportunity, and active pipeline stage holds insight into how your business grows. Migration should protect that intelligence and not dilute it with outdated or irrelevant records.
Old, incomplete, or irrelevant deals create clutter and make pipeline analysis harder to trust. A strong migration strategy prioritizes:
Selective migration improves reporting accuracy and keeps your pipeline focused on what drives revenue today. Carrying excessive historical data increases noise and reduces clarity across dashboards and forecasts.
Your pipeline structure should reflect how your sales team operates today. Start by documenting your current pipeline, then map out your ideal future state before aligning legacy data to the new structure.
Effective deal stages should be tied to clear, trackable actions such as:
Each stage should have defined criteria and property requirements that must be met before a deal can move forward. This maintains consistency across your team and protects reporting accuracy.
For businesses with multiple revenue streams, separate pipelines improve visibility and forecasting. For example:
If your sales process involves quoting specific products, SKUs, or pricing tiers, set up products and line items before importing deals. This ensures revenue data connects correctly to what was actually sold.
Each deal connects to contacts and companies that shape the buying decision. These relationships provide the context needed for accurate reporting and sales alignment.
Every deal record should include:
To preserve these relationships during migration, ensure your data includes consistent identifiers across files. This often involves using shared columns such as deal ID, company name, or another common reference point to link records correctly.
Creating an external ID field for each deal adds another layer of reliability. This stores the unique identifier from your legacy system, which becomes a reference point for future updates, re-syncs, or data backfills.
Without these associations, deals become disconnected from the accounts and people behind them, weakening attribution and reducing visibility for your team.
Deal properties carry the details behind each opportunity. These fields turn raw data into actionable insights for forecasting and strategy. Focus on migrating properties that support analysis and decision-making, such as:
Certain fields should be treated as non-negotiable. Amount, close date, and deal owner must be populated to ensure dashboards and forecasts function immediately after migration.
Data formatting also plays a direct role in accuracy. Currency fields should use numeric values with decimals and no symbols to prevent calculation errors inside reports.
Migration should create a system that is easy to use and easy to trust. Moving every deal ever created often leads to confusion rather than clarity.
Technical limitations also play a role in how historical data is preserved. HubSpot does not support backdating system-generated deal stage timestamps. During import, stage changes are recorded at the time of migration, not at the original historical date.
To maintain visibility into historical progression, create custom date properties for each key stage milestone. These fields store the original stage entry dates and support accurate reporting on deal velocity and time in stage.
Preparation and validation strengthen the final result:
A refined dataset helps your team track pipeline health with confidence, forecast revenue more accurately, and analyze deal progression without distorted timelines.
Lifecycle stages and activity data define how every contact moves through your revenue system. These elements connect marketing efforts to sales outcomes and give your team a clear view of what drives conversions. Poor structure at this level leads to broken attribution, unreliable reporting, and misalignment across teams.
Aligning legacy lifecycle stages with HubSpot requires exact matches for picklist values. Even small inconsistencies in naming or structure can split your data into multiple versions of the same stage, which breaks reporting and segmentation.
Each stage should reflect a clearly defined point in your funnel, with criteria tied to real actions. In traditional sales-led environments, this might include qualification or opportunity creation. In product-led environments, lifecycle movement often depends on behavioral triggers such as:
Clear definitions ensure lifecycle stages act as a shared language across marketing, sales, and operations, rather than a set of loosely interpreted labels.
Lifecycle stages should follow a structured progression that reflects real buyer movement across your funnel. Uncontrolled stage movement leads to inconsistent reporting and unreliable automation.
A controlled progression ensures:
Automation plays a central role in maintaining this structure. Lifecycle stages can update based on defined actions such as form submissions, product activity, or deal creation, which reduces manual errors and keeps data consistent across the system.
Migrating historical activity ensures your team has full visibility into past engagement. These records populate the contact timeline and give sales and marketing teams the context needed to understand each relationship.
Focus on high-intent activities such as:
Some limitations require additional handling. Primary email history can often transfer as notes through contact exports, but two-way sync history from Gmail or Outlook integrations typically remains in the original inbox. To maintain context, add a manual note in the contact record that directs users to archived communication sources.
Filtering out low-value or outdated activity prevents clutter and ensures your CRM reflects meaningful engagement rather than noise.
Lifecycle stages and activity data form the foundation of attribution. Together, they explain how prospects move from initial engagement to revenue.
Accurate attribution depends on:
Well-structured activity tracking also supports internal performance analysis. Managers can build reports on metrics such as demos delivered, calls logged, and conversion rates between stages. Using notes and activity records ensures every interaction contributes to a complete narrative on the contact timeline.
Establishing this structure early ensures every future interaction feeds into a reliable attribution model. Your team gains a system that shows exactly how and where conversions happen.
HubSpot connects marketing platforms, sales tools, support systems, billing software, and data warehouses. Migration without mapping these dependencies creates data conflicts, broken workflows, and inconsistent reporting across systems.
Most organizations rely on multiple tools that send or receive CRM data. These systems extend beyond core sales and marketing platforms and often include communication, enrichment, and operational tools.
A complete audit should document every active integration, including:
Each system should be reviewed to understand what data flows into HubSpot, to other systems, and which fields act as the source of truth. Sales and marketing teams depend heavily on these connections. A missing or broken integration can stop workflows immediately, whether that involves email syncing, lead enrichment, or deal updates.
Every field in your CRM should have a clearly defined system of record. Many data points originate outside of HubSpot, and without ownership rules, systems compete to overwrite each other.
Examples include: billing and payment data from platforms such as Stripe, product usage data from internal systems, and enrichment data from third-party tools.
Clear ownership becomes even more important during migration, as multiple systems may attempt to sync data at the same time.
Integrations rely on specific fields to function correctly. Many legacy systems contain custom properties built over time, often without documentation or a consistent structure. Audit all custom fields and identify which ones are required for integrations such as enrichment tools or support platforms.
Each retained field should have a clear business purpose, the correct data type, and consistent naming conventions.
Some integrations, particularly enrichment tools like Clearbit or Apollo, depend on precise field mappings to route incoming data into the correct HubSpot properties. Misaligned fields result in incomplete or misplaced data, which reduces the value of those tools.
Integrations rely on APIs and sync rules to move data between systems. These connections must be tested before full migration to prevent errors at scale.
Key validation steps include:
Technical limits also need to be considered. APIs enforce rate limits, and high-volume migrations can trigger “429” errors when call thresholds are exceeded. To reduce this risk, use batch APIs for bulk operations, cache results where possible, and stagger large data transfers.
Confirm the cancellation terms of your existing CRM. Many providers require a 30-day notice period before renewal. Missing this window can lock you into another billing cycle, even after migration is complete.
Export a full snapshot of your database before any changes begin. Use CSV exports or a dedicated backup tool to capture all objects and properties. This backup acts as your recovery point in case of import errors, data loss, and incorrect mappings.
Clean your data before it enters HubSpot. Remove test records, invalid or bounced email addresses, and outdated or irrelevant contacts. Avoid importing your entire historical database. Focus on engaged contacts with activity in the last 12 months, such as email engagement, meetings, or deal involvement.
Map every source field to its destination in HubSpot using a structured spreadsheet. For each property, document field name and internal name, business use case, and the owner responsible for maintaining it. Exclude properties with no clear purpose or low usage. Fields with near-zero fill rates or no updates in recent months add complexity without improving insight.
Define how records will be identified to prevent duplication during import. Standard identifiers include: “Contacts → primary email address” and “Companies → domain name.” For other objects, create an external ID field that stores the unique identifier from your legacy system.
Standardize your data to match HubSpot’s formatting requirements before import. Key formats include: “Dates → YYYY-MM-DD”, “Phone numbers → include “+” and country code”, “Country and state → ISO codes”, and “Emails and domains → lowercase only”
Run a test import before moving your full dataset. Use a sample of around 100 records per object to validate your setup. A small batch helps surface edge cases early. Fixing issues at this stage prevents large-scale errors that are harder to correct later.
A HubSpot migration shapes how your revenue engine runs long after the data transfer is complete. Every decision you make, from which records you include to how you structure pipelines and lifecycle stages, directly affects how your team sells, markets, and reports.
The effort you invest in cleaning, mapping, and validating your data now directly shapes how your CRM performs after migration. It determines whether your system becomes something your team relies on daily or one they avoid due to poor data and broken workflows.
To move in the right direction, you can start by assessing your current setup using a Portal Audit Checklist. From there, building a stronger foundation through our HubSpot Onboarding Services helps ensure your CRM is structured and ready to support long-term growth.

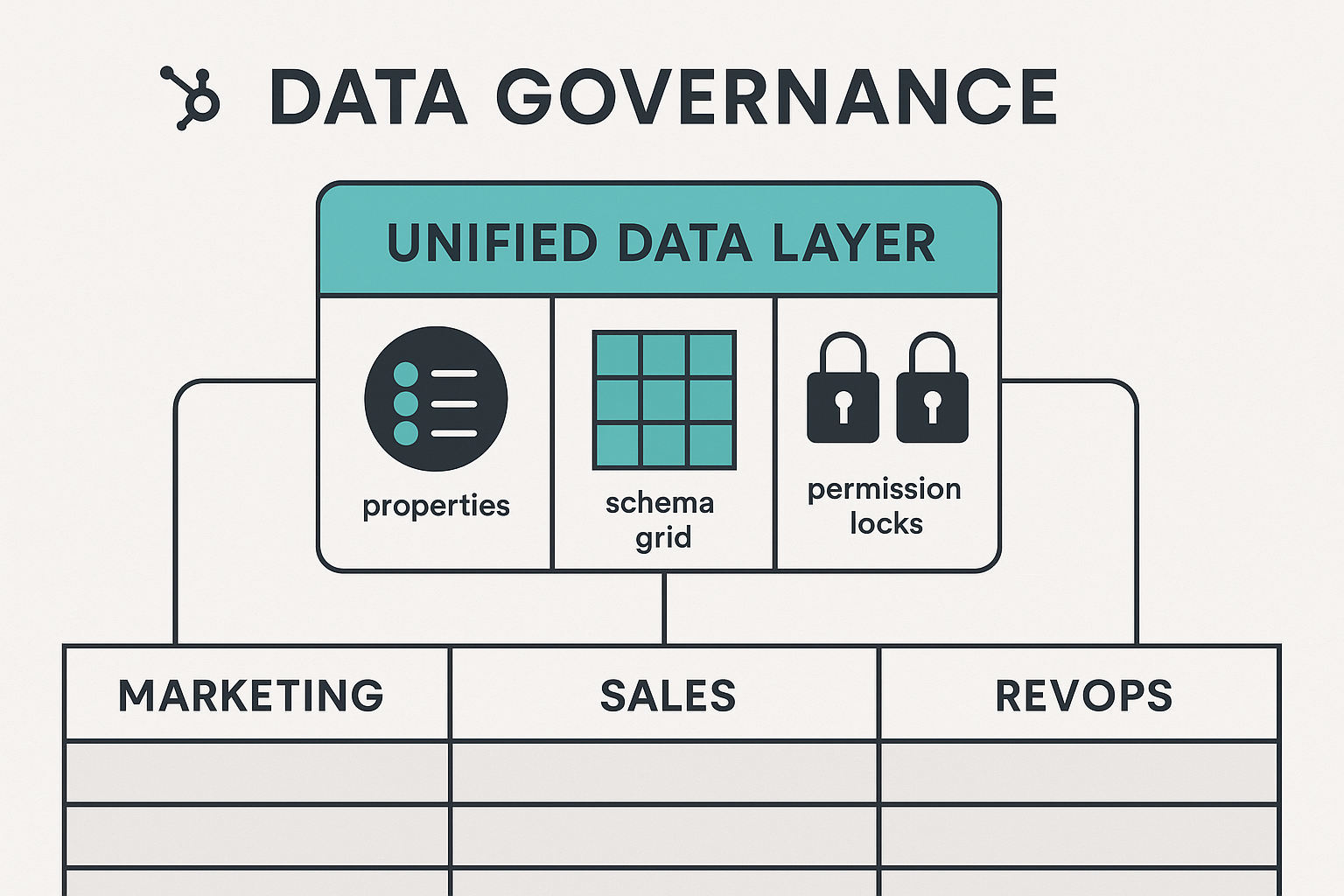
Most CRM environments evolve without a defined schema strategy. Teams create properties to solve immediate problems, integrations introduce new...
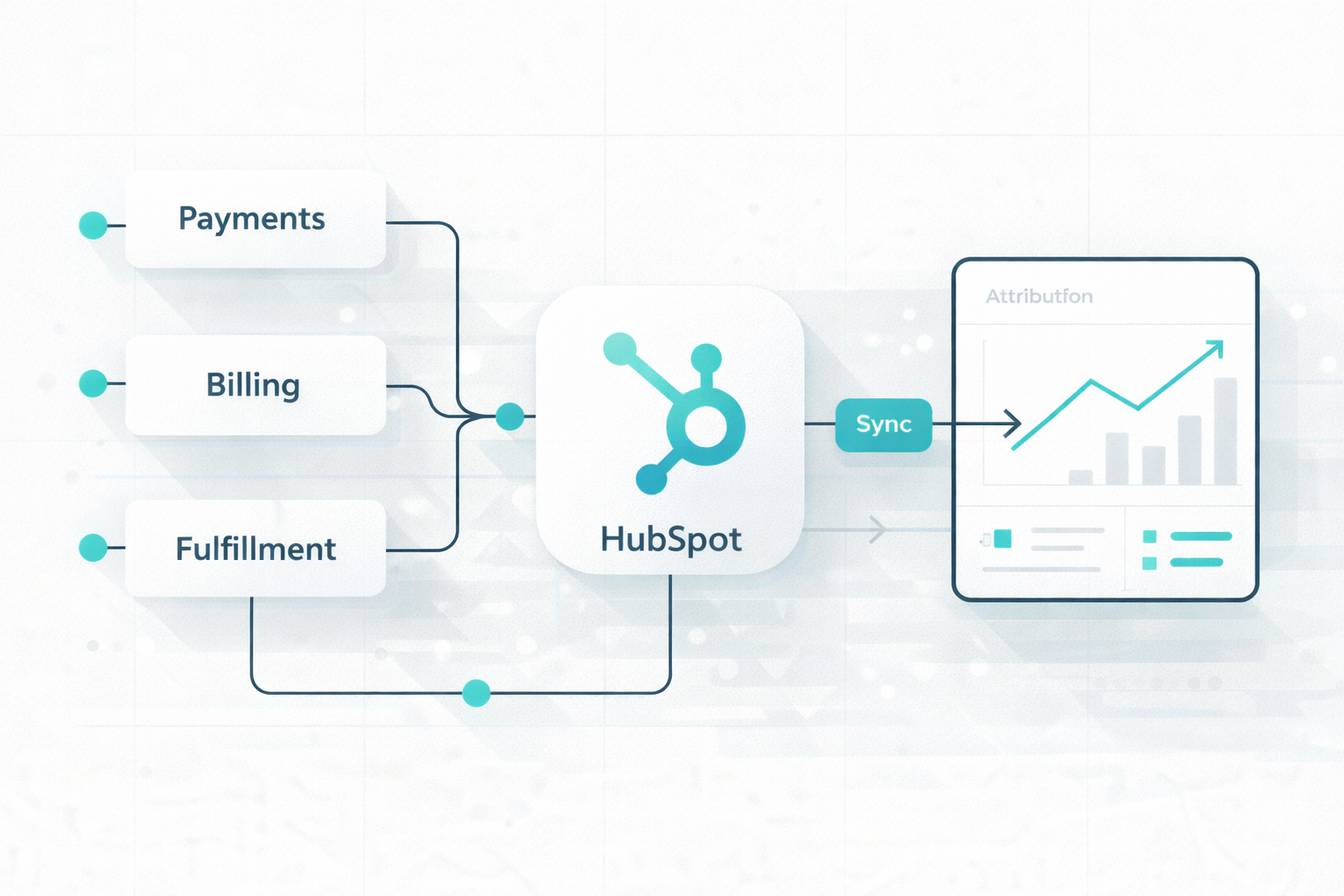
The modern enterprise tech stack has shifted from a single system to a mix of specialized SaaS tools. That shift creates a problem: CRM, payments,...
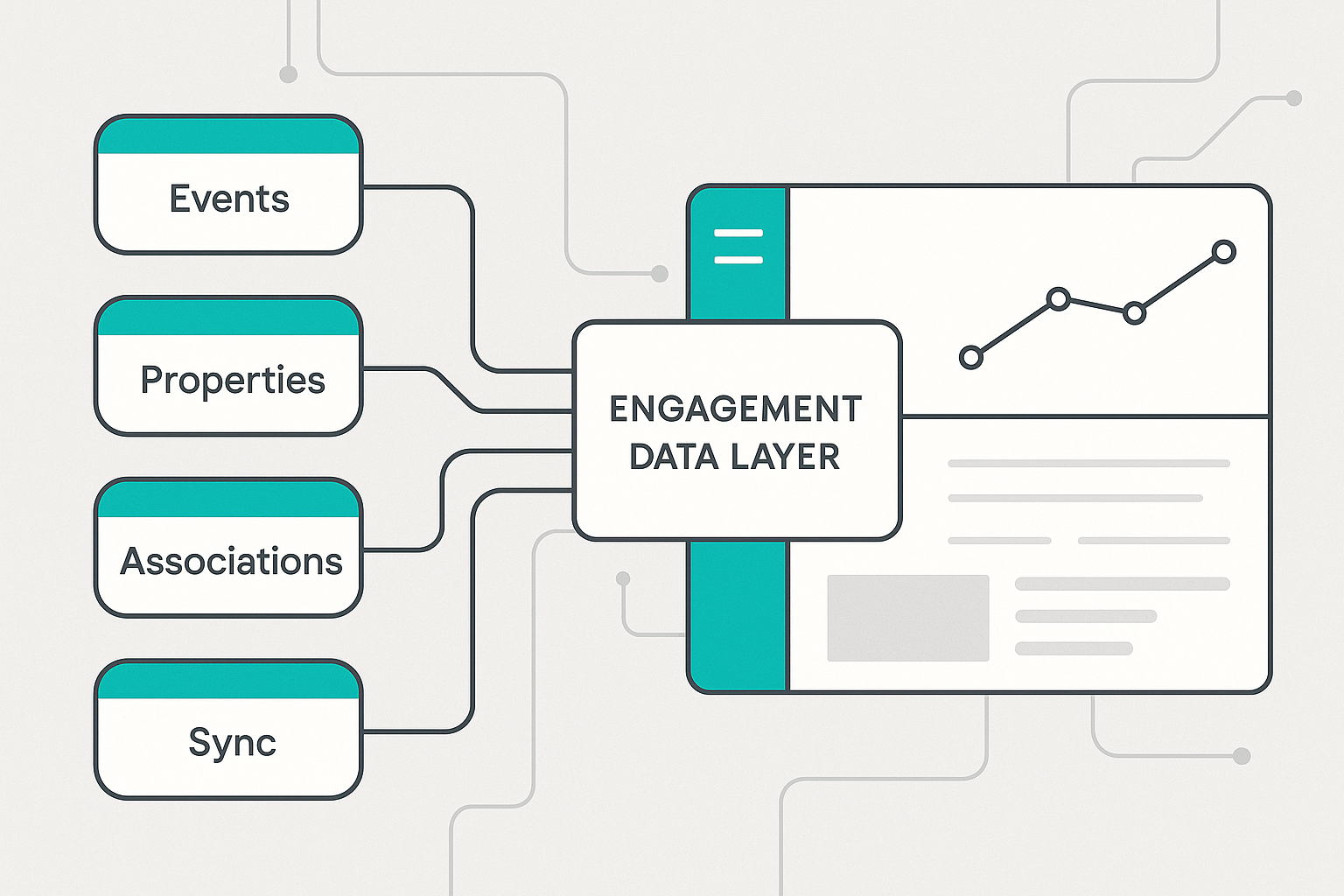
How to Build an Engagement Data Layer for Reliable HubSpot Reporting Consistent and accurate HubSpot reporting starts with the structure behind the...