
.png?width=170&height=170&name=Round%20Blog%20Thumbnail%20(51).png)
 Campaign Creators
Campaign Creators
HubSpot Migration Without Losing System Integrity
Most discussions about HubSpot migration focus on data movement, timelines, and tooling. That framing misses the real decision you are facing. This...
Free assessments, knowledge, and expert content for your HubSpot.
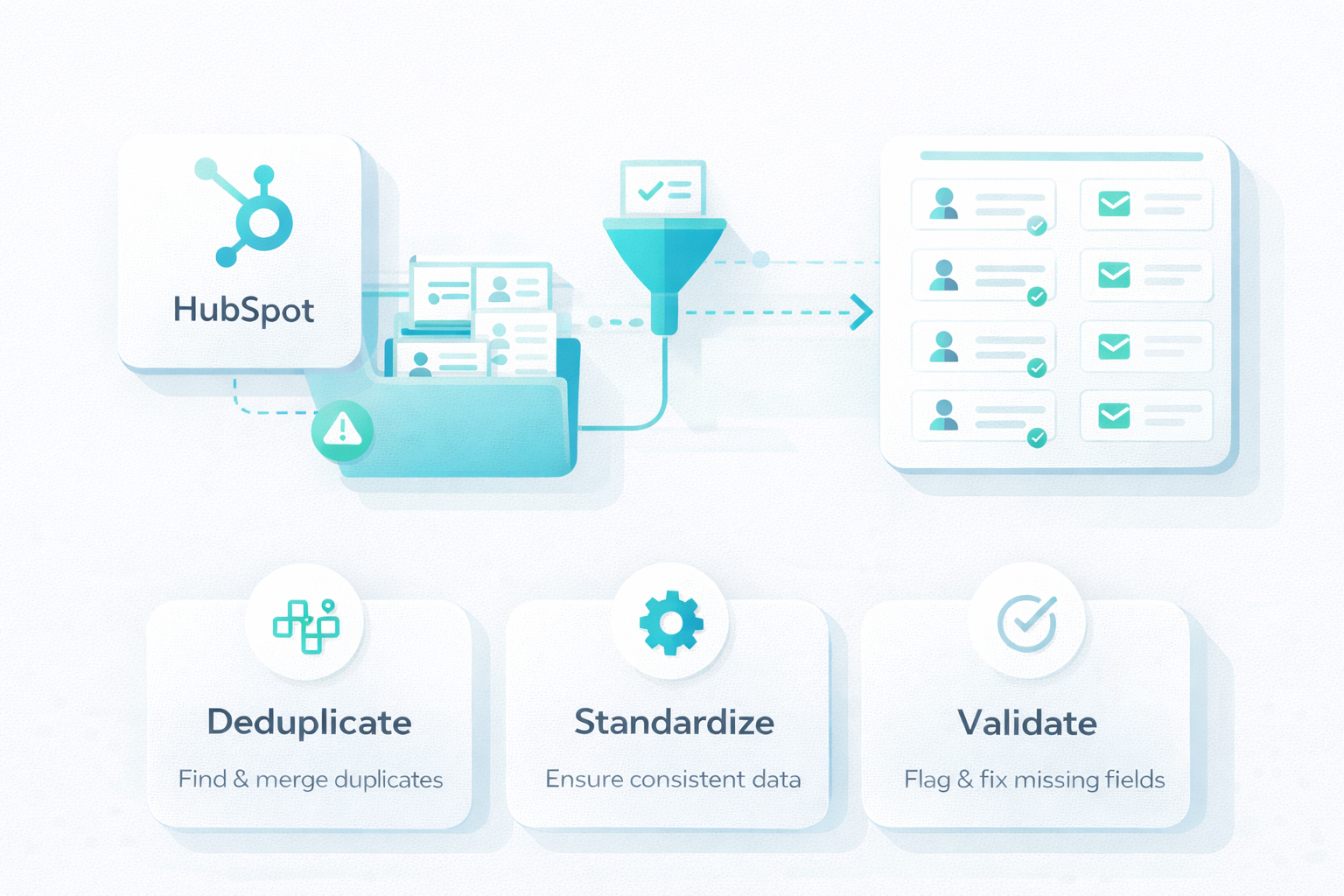
When your system holds conflicting information, each team works from a different version of reality. Marketing sees one story, sales sees another, and finance trusts neither without verification.
This shows up in measurable ways:
A HubSpot data cleanup standardizes how data is defined, how it moves across systems, and how teams use it day to day. With consistent structure and usage, HubSpot becomes a reliable source of truth.
Data cleanup isn’t maintenance. It affects how accurately you forecast, how confidently you make decisions, and how your team drives revenue.

Alt Text: two-executives-analyzing-impact-of-bad-crm-data
Bad data directly affects how revenue is measured, forecasted, and acted on. When your system holds inconsistent information, reporting pulls from mixed logic, segmentation loses accuracy, and forecast inputs start to vary depending on who is using the system.
These issues typically show up as overlapping properties, inconsistent field usage, duplicate records, and conflicting lifecycle definitions across teams.
Most HubSpot portals start with a simple structure. A few pipelines, a defined set of properties, and clear ownership across teams. As your business grows, that structure expands. New campaigns introduce new fields. Sales teams adjust processes. Integrations bring in external data with their own formats and definitions. Eventually, this creates overlaps.
You end up with multiple properties tracking the same concept, slightly different naming conventions, and fields that no longer serve a clear purpose. More than 60% of portals exceed 500 properties, which makes it harder to know which data to trust.
If teams don’t know which fields to use, it will end up with these:
The result is slower decision-making and misaligned execution. Campaigns target the wrong audiences, and pipeline reports lose accuracy. That directly impacts revenue planning and performance.
A common pattern looks like this:
Each step introduces a small inconsistency, and eventually those differences compound.
Inconsistent data affects how each team operates day to day.
Fixing these issues can lead to:
This is where data cleanup shifts from a backend task to a direct driver of revenue performance.
A structured cleanup strategy addresses how data is defined, how it moves through your system, and how it is maintained over time. This approach moves through five connected areas:
Each step builds on the previous one, allowing your system to become more stable and reliable over time.
Rather than reviewing every field in your system, it helps to begin with a focused audit centered on data that directly influences decisions. Fields tied to deal progression, segmentation, attribution, and forecasting tend to have the greatest impact, since they shape how your team understands pipeline and performance.
Once those fields are identified, evaluate them across three dimensions: completeness, consistency, and duplication. These dimensions work together, and gaps in one often affect the others.
For example, completeness looks at whether key fields are consistently filled in. When only a portion of deals include a close date, revenue timing becomes unclear, which makes forecasts unreliable. Consistency ensures that values follow a standard format, so variations like “United States,” “US,” and “USA” don’t fragment reporting.
In many CRM systems, the same concept appears across multiple fields because different teams created their own versions over time. For example, you might see “Lead Source,” “Original Source,” and “Marketing Source” all being used to capture similar information. Although each field may have been created with a specific purpose, the overlap introduces confusion and leads to inconsistent reporting.
To resolve this, each concept needs to be consolidated into a single, clearly defined property. This reduces ambiguity and ensures that reports pull from a consistent source of truth.
A practical way to approach this includes:
As part of this process, it also helps to standardize inputs. For instance, instead of allowing free-text entries for industry, you can use a predefined dropdown so that all entries follow the same structure.
Grouping properties into logical categories such as lifecycle stages, segmentation data, and revenue fields further improves usability and reduces errors during data entry.
Duplicates often create confusion because they split information across multiple records. As a result, engagement history becomes incomplete, outreach can be repeated, and pipeline metrics lose accuracy.
To address this, it helps to begin with clear matching rules, such as using email for contacts and domain for companies, so that duplicate records can be identified consistently.
Before merging records, it’s important to define how data should be preserved. In many cases, one record may contain recent activity but missing fields, while another holds more complete information but lacks engagement. A structured merge approach ensures that you retain both the most relevant activity and the most complete data.
At the same time, standardization ensures that data behaves consistently across the system. Fields like country, industry, and lifecycle stage need to follow a single format so that reporting and automation work as expected.
A consistent approach typically includes:
Records become more complete, reporting becomes more accurate, and the overall system becomes easier to trust when duplication and standardization are handled together.
Each team should take responsibility for the data they rely on, which creates accountability and reduces ambiguity. RevOps typically manages lifecycle stages and pipeline structure, Marketing Ops oversees source and campaign data, Sales Ops handles ownership and territory fields, and Finance manages revenue-related metrics.
However, ownership goes beyond access. It also includes defining allowed values, setting expectations for when fields should be updated, and reviewing data quality regularly.
For example, if Marketing owns “Original Source,” that team defines the accepted values, ensures every new contact includes a source, and reviews accuracy regularly.
To keep this consistent, ownership should be supported by:
This creates a system where expectations are clear and consistently applied across teams. To reinforce this over time, governance can be formalized through structured processes such as quarterly schema reviews and monthly instrumentation sprints, often supported through a Modular Retainer Model.
Even with clear ownership in place, maintaining data quality through manual effort alone becomes difficult as your system grows. For that reason, long-term consistency depends on preventing issues before they enter the system.
This begins with embedding simple controls into your workflows. Validation rules can ensure that required fields are completed before records move forward, and dropdown fields can replace free-text inputs to reduce variation. Automated alerts can notify owners when key data is missing or incorrect, allowing issues to be addressed early.
You can also introduce duplicate detection tools that flag potential matches before new records are created, which reduces the need for cleanup later.
An effective setup often includes:
This shifts your system from reactive cleanup to proactive control. Data stays consistent as it enters the system, and reporting remains reliable without constant intervention.
In our guide, How to Design HubSpot Automation for Clean Data and Better AI, you’ll see how automation can go beyond validation to support cleaner inputs, more reliable reporting, and stronger AI performance.
In most cases, breakdowns follow a few common patterns:
It only resets the data temporarily when cleanup is treated as a one-time effort. As new data enters under the same conditions, inconsistencies reappear. This is why many teams see progress early on, only to find that results fade within a few months.
Focusing only on surface-level fixes creates a similar issue. Removing duplicates or reducing the number of properties can make the system look cleaner, but it doesn’t resolve deeper inconsistencies in lifecycle stages, attribution, or revenue tracking. As a result, reports may still reflect conflicting logic, even if the data appears more organized.
Misalignment across systems introduces another layer of complexity. When your CRM, ERP, billing, and support platforms define key data differently, those differences continue to flow back into HubSpot. This creates data drift, where records gradually lose alignment across systems.
These patterns reinforce each other. Without consistent definitions, clear ownership, and built-in controls, the system naturally returns to an inconsistent state.

Once data is standardized, the workflows or processes in a CRM start working as intended because they rely on consistent inputs.
This leads to measurable improvements:
The impact becomes clear as systems begin to produce more consistent and usable outputs. At the same time, 95% of AI initiatives struggle due to poor data quality, which shows how strongly performance depends on clean inputs.
For example, lead scoring becomes more accurate when lifecycle stages and engagement data follow a consistent structure. Forecast models stabilize when deal stages and close dates are reliable. AI recommendations improve when the system can trust the data it receives.
Clean data sets the limit for what your system can deliver. When that foundation is strong, every layer built on top of it performs better.
A CRM rarely fails in obvious ways. Instead, issues build through small inconsistencies, extra manual work, and a gradual loss of confidence in the data.
A structured HubSpot data cleanup strategy brings the system back into alignment by creating consistent definitions, assigning clear ownership, and preventing new issues from entering. As these foundations take hold, reporting becomes more reliable, automation works as expected, and AI outputs become usable.
The result is a system your team can rely on to support daily operations and scale as your business grows.
To get started, you can baseline your current portal using the Portal Audit Checklist and begin putting guardrails in place through HubSpot Onboarding Services. From there, the focus shifts from fixing data to using it with confidence.
For large portals with hundreds of properties and multiple integrations, cleanup usually takes 4 to 12 weeks, depending on complexity and data volume. Timelines extend when restructuring, deduplication, and governance setup happen together rather than as isolated fixes.
Start with data tied directly to revenue decisions, such as deal stages, close dates, lifecycle stages, and source attribution. Fixing these first stabilizes reporting and forecasting before moving into lower-impact fields.
The main risk is breaking reports, workflows, and integrations that depend on existing fields. There’s also a risk of data loss or misalignment if migration rules are not clearly defined before consolidation.
Teams often merge or delete fields without mapping dependencies, which disrupts reporting and automation. Another common issue is failing to standardize values first, which carries inconsistencies into the new structure.
You can avoid disruption by mapping old lifecycle stages to new ones before making changes, then updating reports and workflows in parallel. A phased rollout, starting with testing in a controlled segment, reduces system-wide impact.
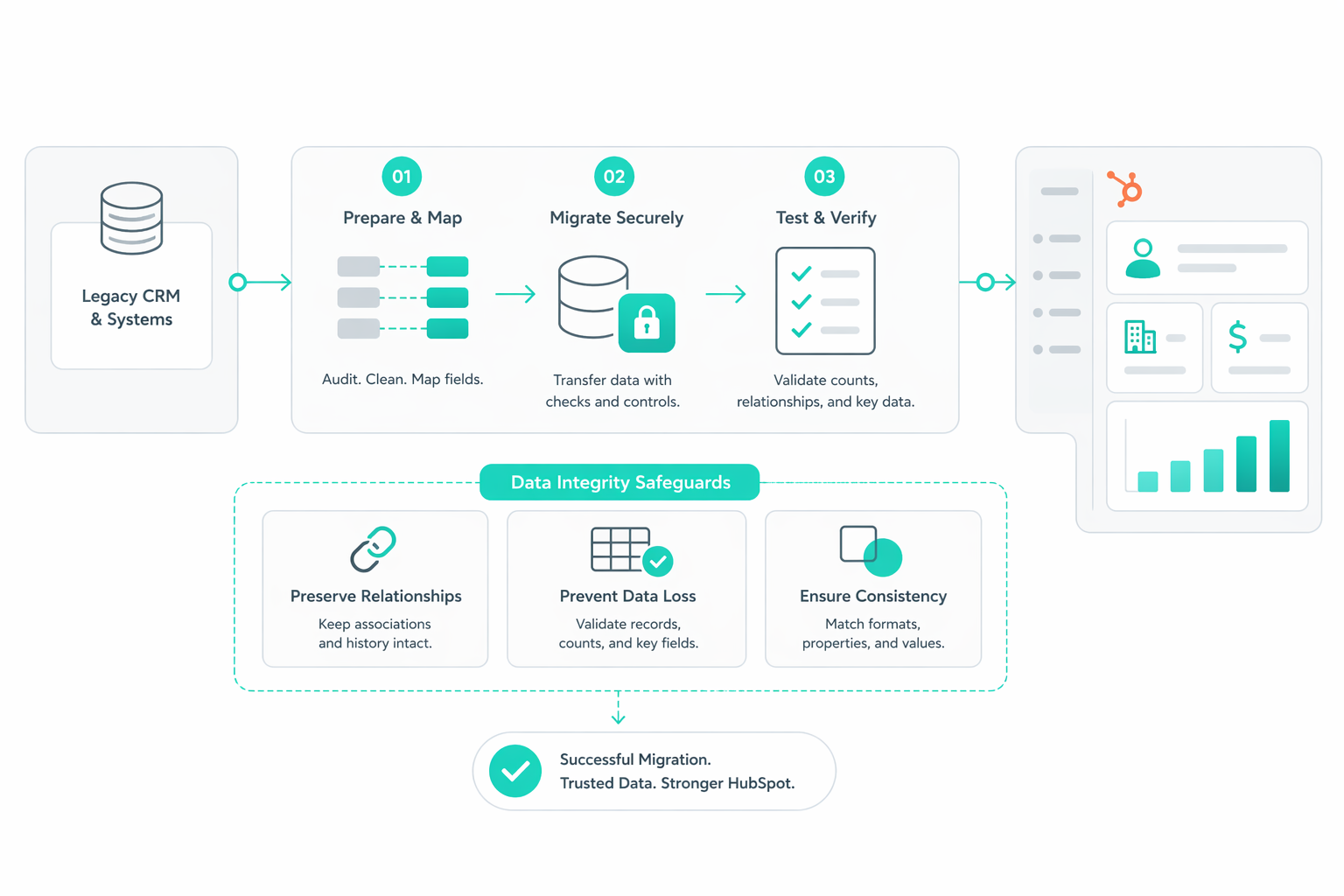
Most discussions about HubSpot migration focus on data movement, timelines, and tooling. That framing misses the real decision you are facing. This...
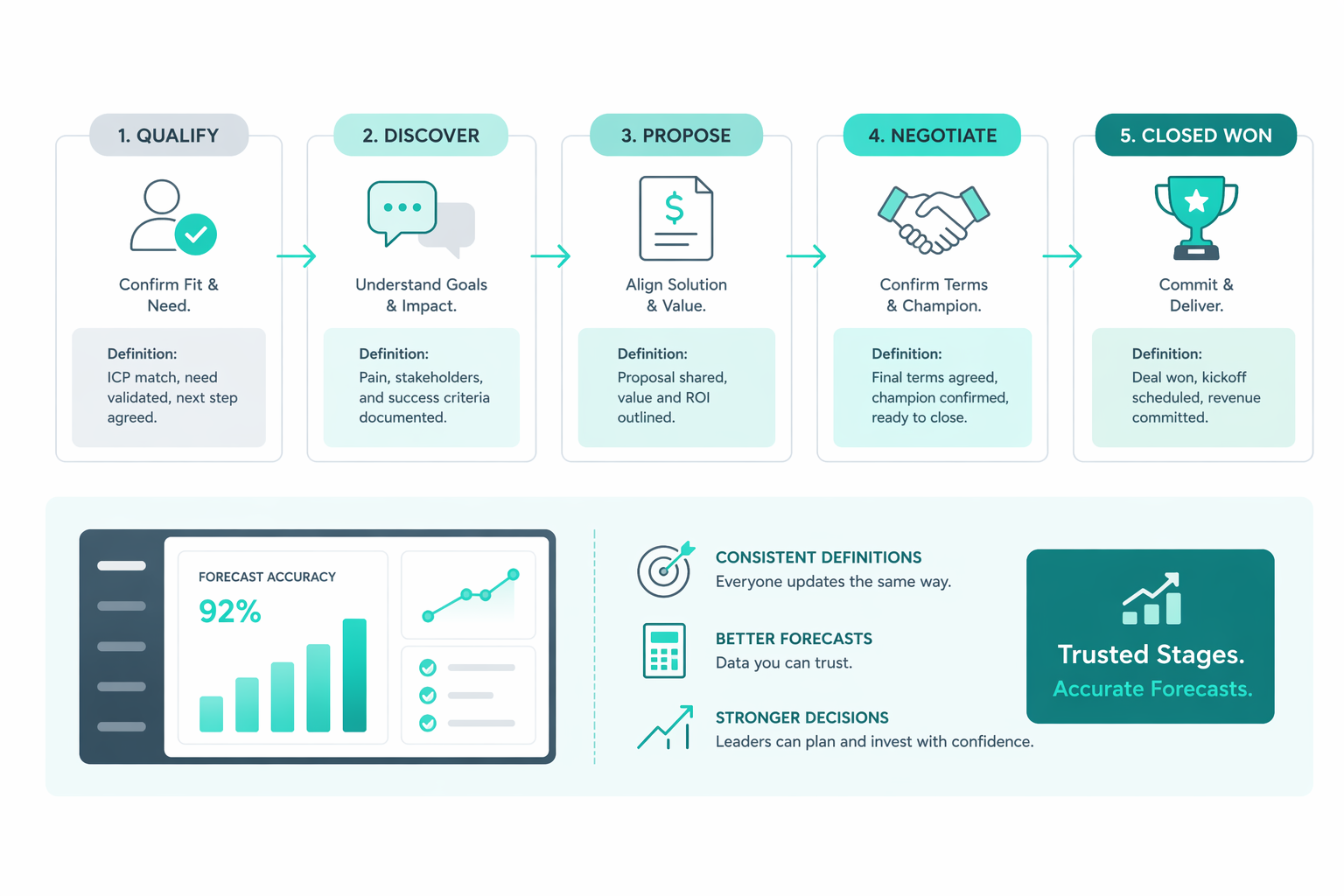
Leadership teams rely on pipeline visibility to judge whether projected revenue reflects real buyer commitment or simply internal optimism. Because...

Healthcare is shifting toward a full patient experience, where you’re expected to deliver the same smooth digital interactions found in retail and...